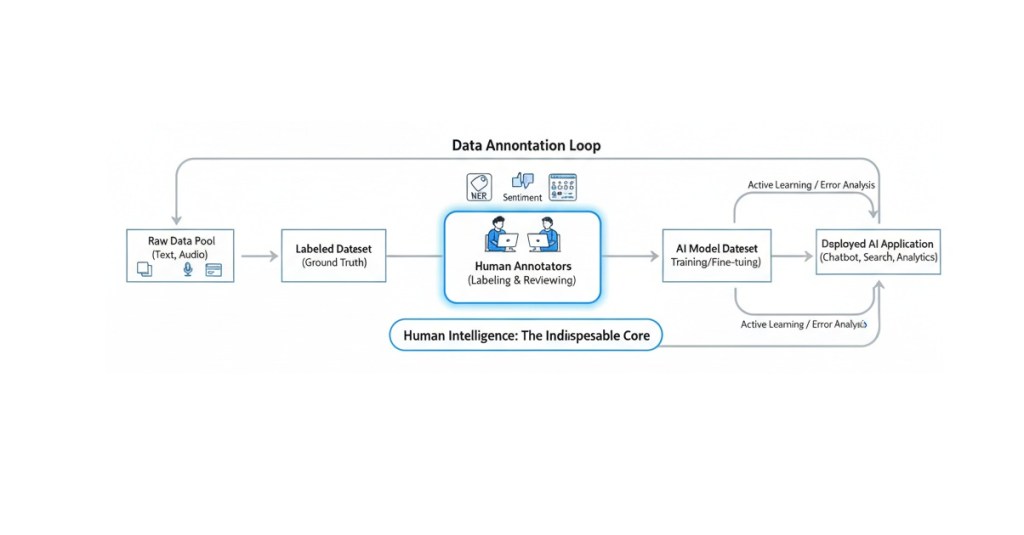
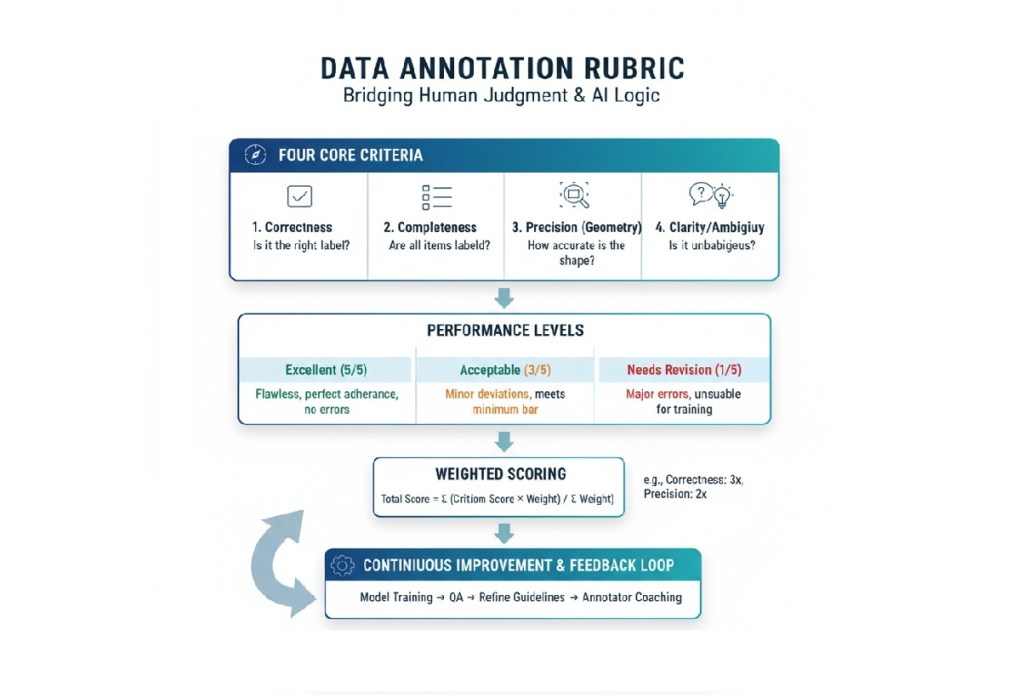
The world of AI is evolving at warp speed, and the backbone of this revolution—data annotation and training—is changing just as fast. For both aspiring and veteran annotators, 2026 is the year where the game shifts from simple micro-tasks to highly specialized, knowledge-driven projects.
The data annotation industry is undergoing a dramatic transformation. What was once dominated by simple microtask platforms offering quick, repetitive work has evolved into a sophisticated marketplace where specialized skills command premium rates. Today’s platforms range from traditional task-based marketplaces to professional hiring platforms that connect elite annotators with long-term, high-value projects.
What was once a niche gig for hobbyists has transformed into a lucrative career path, with freelancers earning anywhere from $15 to $150 per hour, depending on expertise and platform.
If you’re a beginner dipping your toes into this field—perhaps a recent grad with a passion for tech—or a seasoned pro eyeing professional growth, now’s the time to dive in.
The global data annotation market is projected to hit $3.6 billion by 2027, creating millions of remote opportunities. But here’s the catch: the landscape isn’t what it used to be. Gone are the days of endless, mindless microtasks on platforms like the early Amazon Mechanical Turk. Today’s top freelance crowdsourcing platforms emphasize quality over quantity, domain expertise over speed, and long-term contracts over one-off hits.
In this article, we’ll unpack the top 10 platforms to watch in 2026, blending established giants with rising stars like Mercor, Alignerr, and Micro1 AI. We’ll break down the main differences between task-based and hiring-focused models, spotlight the skills in hottest demand, and arm you with actionable tips to apply, thrive, and scale your career.
Whether you’re annotating medical images or fine-tuning LLMs, these insights will help you navigate this rapidly evolving ecosystem—and yes, we’ll stress why ongoing training is your secret weapon for success.
The New Map: Crowdsourcing vs. AI Recruitment Platforms
Before diving into the list, it’s vital to understand the two main business models defining the AI training ecosystem. Knowing which one you’re applying to will completely change your application strategy and work expectations.
| Feature | Direct-Task Platforms (e.g., DataAnnotation.tech, Appen) | AI Recruitment & Vetting Platforms (e.g., Mercor, micro1.ai) |
| Business Model | Provides a marketplace of micro-tasks directly to a vast crowd of contractors. | Acts as an agency to vet highly-skilled freelancers and match them to long-term contracts with companies. |
| Work Type | High-volume, granular, short-duration tasks (e.g., image tagging, chatbot response ranking). | Long-term, contract-based roles (e.g., prompt engineering, expert review, high-level coding). |
| Vetting | Core Assessments/Tests: Highly rigorous, often opaque screening process focusing on quality and adherence to complex rules. | AI-Driven Interviews: Uses AI to screen, score, and interview candidates for technical and soft skills to ensure a perfect project match. |
| Pay Model | Per-task/per-hour (often tiered based on performance/expertise). | Fixed hourly/daily rate, usually higher and more stable. |
| Flexibility | Maximum flexibility—work when projects are available, no minimum hours. | High flexibility, but often requires minimum hours per week/contract duration. |
Nuances & How to Apply
- For Direct-Task Platforms (like DataAnnotation.tech): Success depends entirely on your quality score. You must meticulously follow the (often secret) project guidelines.
- Tip to Apply: Take your time on the core assessment. Prioritize quality and adherence over speed. If they ask for 2-3 sentences, stick to that, demonstrating your attention to detail.
- For AI Recruitment Platforms (like Mercor, micro1.ai, Alignerr): Success hinges on your professional profile and interview performance. These platforms use sophisticated AI tools (like micro1’s “Zara” AI recruiter) to source and vet talent. They aren’t just looking for an annotator; they are looking for a specialist contractor.
- Tip to Apply: Highlight your domain expertise. Show evidence of your professional skills (e.g., “Medical Imaging Specialist,” “Advanced Python Developer”). Treat the AI interview like a real job interview—it’s testing for competence and communication.
The 10 Top Platforms to Watch in 2026
Here are the key players shaping the future of AI data work, segmented by their primary model:
A. The Direct-Task Powerhouses
These are the established platforms that continue to offer a high volume of work, with a growing demand for specialized skill sets.
| # | Platform | Focus | Key Takeaway for Freelancers |
| 1 | DataAnnotation.tech | High-Quality AI Training, LLM/Chatbot Evaluation | Known for higher pay rates and highly complex, specialized tasks (coding, math, creative writing). The gold standard for the new, high-value AI work. |
| 2 | Appen | Scale & Diversity (Image, Text, Audio) | A massive platform with a vast project array. Still the leader for sheer volume and geographical reach. Essential for generalists. |
| 3 | TELUS International AI (formerly Lionbridge) | Linguistic, Search Quality, Geopolitical | Strong focus on cultural and linguistic nuances. Great for those with multilingual skills or deep regional knowledge. |
| 4 | Toloka (by Yandex) | Crowdsourcing & Simple Microtasks | Excellent for beginners and simple tasks. High volume, but generally lower pay. A great starting point for building initial experience. |
| 5 | SuperAnnotate | Advanced Computer Vision & ML-Ops | A platform for serious, tool-driven annotation. Look for roles here if you have prior experience with advanced bounding box, segmentation, or video tracking tools. |
B. The AI Recruitment & Vetting Specialists
These platforms are less about micro-tasks and more about landing you a high-paying, long-term contract as a verified expert.
| # | Platform | Focus | Key Takeaway for Freelancers |
| 6 | Mercor | Top-Tier AI & Tech Talent Matching | Heavily focused on placing senior talent (SWEs, Data Scientists, Mathematics Experts, Biology PhDs) into high-paying contract roles. Requires passing AI-driven technical interviews. |
| 7 | micro1.ai | Human Brilliance for Frontier AI Data | Specifically vets human expertise for cutting-edge AI model training. Their AI recruiter, Zara, streamlines the hiring process for expert annotators and RLHF (Reinforcement Learning from Human Feedback) specialists. |
| 8 | Alignerr | Domain-Specific, High-Security Annotation | Targets complex, sensitive data projects (e.g., medical, finance) where certified, vetted specialists are required. Expertise in niche domains is a major advantage. They also use an AI recrutier (Zara) for the hiring process. |
C. The Specialist & Enterprise Providers
These platforms primarily target B2B contracts but rely on a skilled, managed workforce, offering opportunities for structured, high-quality work.
| # | Platform | Focus | Key Takeaway for Freelancers |
| 9 | Labelbox | Annotation Tooling & Managed Workforce | While primarily a software provider, they run a managed labeling service. Roles here involve high-level quality assurance (QA) and tool mastery. |
| 10 | iMerit | Complex Annotation & Domain Expertise | Specializes in challenging domains like geospatial, medical imaging, and autonomous driving. Look for opportunities here if you have verifiable, high-stakes expertise. |
The Future is Specialization: The New Skill Imperative
The days of simply drawing bounding boxes for minimum wage are rapidly ending. AI can automate most simple labeling. Your value in 2026 comes from what AI cannot do: apply expert-level, human judgment.
Here are the must-have skills for success:
1. Domain Expertise (The “Hard Skills”)
The most lucrative projects require specialized knowledge. You must market yourself beyond “data annotator.”
- STEM Specialization: Projects demand experts in Math (especially high-level calculus and physics), Medicine (radiology, pathology), and Law. AI models are being trained on complex concepts and need subject matter experts to check their output and provide high-quality training data.
- Coding & Prompt Engineering: High-paying roles involve annotating code snippets, evaluating code-generating AI (like GitHub Copilot), and writing challenging, adversarial prompts to test LLMs. A working knowledge of Python, SQL, and natural language processing (NLP) basics is a major differentiator.
- Linguistic & Cultural Nuance: You will be paid a premium to evaluate LLMs for coherence, tone, and cultural appropriateness, especially in low-resource or complex languages.
2. The Core AI Skillset (The “Soft Skills”)
These fundamental skills are non-negotiable across all platforms:
- Laser-Sharp Attention to Detail: A single error can poison a dataset. Your ability to consistently follow complex, multi-page guidelines is the foundation of quality.
- Critical Thinking & Judgement: Many tasks are ambiguous. You need to make a judgment call and provide a clear, logical rationale for your decision.
- Tool Proficiency & Adaptability: Learn the main tool paradigms quickly (e.g., bounding boxes, semantic segmentation). The quicker you adapt to new platform interfaces, the more tasks you’ll unlock.
Your Next Step: Invest in Your Future
The common denominator for success on all top platforms in 2026 is demonstrated, high-value skill. The barrier to entry has never been higher, but the earning potential for qualified experts has never been greater.
Perhaps the most important insight for anyone serious about succeeding in data annotation: investing in training is non-negotiable.
The gap between entry-level annotators and those commanding premium rates often comes down to training and skill development.
Many e-learning platforms offer courses on AI fundamentals, machine learning basics, and some annotation notions. Many are free or low-cost, making them accessible investments in your earning potential (read our article on creating your own 8-week study plan here!).
Additionally, several annotation platforms offer their own training programs—take advantage of every opportunity. Even if the immediate compensation for training tasks is low, the long-term benefit of accessing higher-paying work far outweighs the short-term cost.
Take a look also to our specifically designed self-paced online course (course page here) to save time and close the gap in few weeks!
Looking Ahead: The Future of Data Annotation Work
The data annotation field is at an inflection point. While some fear that AI will automate annotation work, the reality is more nuanced. As AI systems become more sophisticated, the need for high-quality human feedback becomes more critical, not less. However, the nature of that work is evolving toward more complex evaluation tasks that require genuine expertise and judgment.
The winners in this evolving landscape will be those who commit to continuous learning, develop genuine expertise in specific domains, and adapt to new types of annotation work as they emerge. The platforms highlighted here represent some of the current leaders, but staying informed about new entrants and shifts in the industry will remain important.
For beginners, the opportunity to enter this field has never been better, with accessible entry points and clear pathways to skill development. For professionals, the chance to leverage your expertise into meaningful, well-compensated remote work is real and growing.
The key takeaway is this: success in data annotation in 2026 and beyond requires viewing it as a genuine profession deserving of serious investment in skill development, not just as casual side work. Those who approach it with that mindset will find abundant opportunities in this essential, growing field powering the AI revolution.
How are you going to tackle the next challenges for AI trainers and annotators? Share your thoughts below and stay tuned for the next article about mastering the AI interview!