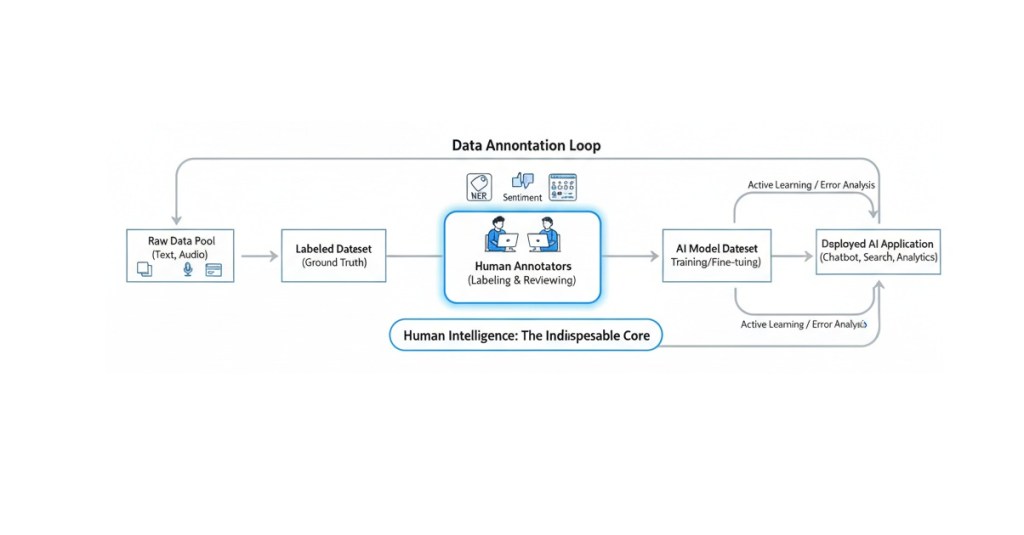
In our last deep dive, “The 2026 AI Data Annotation Landscape: Top 10 Platforms to Watch & How to Thrive“, we explored how the landscape of AI training has shifted. We saw the rise of specialized players like Mercor, Micro1, and Mindrift, which have largely replaced the “click-work” chaos of the early 2020s with sophisticated, high-stakes vetting.
But as we hinted in that article, there is a new “final boss” standing between you and those $50+/hour expert annotation contracts: The AI Interview Avatar.
The hardest part of getting hired on premium platforms isn’t necessarily the technical assessment—it’s often the “face-to-face” interview with an AI avatar.
For many freelancers, this is a terrifying new frontier. It feels unnatural. You can’t read body language, you can’t charm a robot with small talk, and the fear of being misunderstood by an algorithm is paralyzing. Furthermore, on some platforms, the AI is actively scoring your soft skills, English proficiency, and technical knowledge in real-time.
A failed interview here often means an instant rejection, sometimes blocking you from applying again for months.
If the thought of sitting across from a digital human like Zara (Micro1’s AI recruiter) or Mercor’s hyper-logical screening bot makes your palms sweat, you aren’t alone. The “Uncanny Valley” of recruitment is real, and it’s a hurdle that’s currently filtering out thousands of brilliant annotators simply because they don’t know how to talk to a machine.
Today, we’re going to demystify the process. This is your definitive playbook for conquering the AI interview and proving to the algorithms that you are the human expert they need.
The Shift: Why a Bot is Interviewing You
In 2026, the volume of applicants for “AI Trainer” and “RLHF Specialist” roles is staggering. A single opening can attract 10,000 global freelancers in 48 hours. Human HR teams can’t scale to meet that, but an AI interviewer can.
These avatars aren’t just fancy chatbots. They are powered by the very models you are applying to train. They evaluate:
- Technical Depth: Can you explain why an LLM hallucinated in a specific scenario?
- Communication Clarity: Can you distill complex edge cases into simple instructions?
- Reasoning Patterns: Do you jump to conclusions, or do you follow a structured logical path?
- Consistency: Does your spoken experience match the “latent space” of your resume?
The opportunity here is massive: these bots don’t care about which country you’re in or what’s on your head. They care about your utility. Succeeding here is the ultimate meritocracy.
Here is the playbook on how to prepare for, navigate, and succeed in these high-stakes AI interactions, irrespective of your native language.
1. Know Your “Opponent”: What the AI is Actually Looking For
Forget human HR interviews. The AI doesn’t care about your “vibes” or cultural fit in the traditional sense. It is programmed to evaluate specific parameters rigorously:
- Clarity and Conciseness: Can you explain a complex concept simply without rambling?
- Keyword Relevance: Are you using the correct industry terminology (e.g., “RLHF,” “semantic segmentation,” “zero-shot prompting”) in the right context?
- Instruction Adherence: If the AI asks for a 60-second answer, do you stop at 60 seconds? If it asks for two examples, do you provide exactly two?
- Logical Structuring: Do your answers have a clear beginning, middle, and end?
The Golden Rule: AI hates ambiguity. Be literal, be structured, and be direct.
2. Mastering the “Avatar Tongue”
Talking to an AI requires a subtle shift in how you structure your sentences. You need to be Natural yet Structured.
The “Keyword-First” Approach
Unlike humans, who might find repetition annoying, AI interviewers look for “concept clusters.” If the role is for an SFT (Supervised Fine-Tuning) specialist, ensure you use the terminology explicitly. Don’t just say “I checked if the AI was right.” Say, “I performed a multi-dimensional evaluation of the model’s output against the provided ground truth, focusing on factuality and instruction-following.”
The STAR-R Method
You know the STAR method (Situation, Task, Action, Result). For AI interviews in 2026, you must add the final R: Reflection.
- Example: “After improving the dataset’s labeling consistency (Result), I realized (Reflection) that the initial ambiguity stemmed from poorly defined edge cases in the prompt, which taught me to always stress-test guidelines before a full production run.”
- Why? AI avatars are programmed to look for “Growth Mindset” and “Metacognition.” They want to see that you can think about your own thinking.
Handling the Interjections
Bots are notorious for “active probing.” If you start rambling, the AI might interject with: “Can you dive deeper into the specific trade-offs of that decision?”
The Pro-Tip: Do not get flustered. This isn’t a sign of failure; it’s a “Branching Logic” trigger. It means the AI found your point interesting and wants to verify your depth. Pause, acknowledge the bot, and provide a 2-3 sentence technical deep-dive.
3. The Pre-Interview Checklist
Treat this more seriously than a Zoom call with a human. A human might forgive a glitchy microphone; an AI might interpret bad audio as poor communication skills.
- Hardware is Non-Negotiable: Use a high-quality headset with a noise-canceling microphone. Do not rely on your laptop’s built-in mic. Clear audio input is crucial for the AI to transcribe and analyze your speech accurately.
- The Environment Matters: Ensure a neutral background and absolute silence. Background noise (dogs barking, traffic) can confuse speech-to-text algorithms, leading to disastrous misunderstandings of your answers.
- Rehearse Your Resume “Data Points”: The AI will likely ask you to walk through your experience. Don’t tell stories; provide data points. Instead of “I did some annotation management,” say, “I managed a team of 20 annotators for a 50,000-image computer vision project using bounding boxes, achieving a 98% QA acceptance rate.”
4. Navigating the Interview: Handling Misunderstandings
The biggest fear is the AI misinterpreting you or getting stuck in a loop. Here is how to handle common friction points:
Scenario A: The AI asks a confusing or poorly phrased question.
- Do NOT: Guess the answer or ramble hoping to hit a keyword.
- DO: Calmly ask for clarification using simple phrasing. “Could you please rephrase that question?” or “Are you asking about [Topic A] or [Topic B]?” Most advanced AI recruiters are programmed to handle clarification requests.
Scenario B: You realize the AI misunderstood your previous answer.
- Do NOT: Get frustrated, sigh, or raise your voice. The AI analyzes tone.
- DO: Use “signposting” language to correct the record. Say calmly: “To clarify my previous point on [Topic X], I meant that…”
Scenario C: You need thinking time.
- Do NOT: Fill the air with “um,” “uh,” or long silences.
- DO: Use professional placeholders. “That’s an interesting question. Let me structure my thoughts on that for a moment.”
5. Critical Advice for Non-Native English Speakers
If English is not your first language, these AI interviews can feel doubly intimidating. However, many platforms are actively seeking diverse global talent. The AI isn’t looking for a perfect American or British accent; it is looking for intelligibility.
- Speed Kills Clarity: The biggest mistake is speaking too fast out of nervousness. Anxiety tightens your throat and thickens accents. Slow down by 20%. Enunciate your words clearly. The AI needs time to process your phonemes.
- Simplify Your Syntax: Do not try to use complex, winding sentence structures to sound sophisticated. Stick to standard Subject-Verb-Object sentences. Short, punchy sentences are easier for AI models to process correctly.
- Focus on Domain Vocabulary: You might struggle with casual idioms, but you must master the technical vocabulary of the job. If you are applying for a math role, ensure your pronunciation of mathematical terms is flawless.
- Don’t Apologize: Never start an interview by apologizing for your English. It flags a lack of confidence to the AI’s sentiment analysis. Speak with authority on the topics you know.
6. Instant Failures: Three Mistakes to Avoid
- Interrupting the Bot: Wait for a clear 1-2 second pause after the AI finishes speaking before you begin. Overlapping audio is a nightmare for transcription algorithms and will ruin your score.
- Being Generic: If asked, “What is your experience with LLMs?”, do not say, “I have used ChatGPT.” Say, “I have experience prompting LLMs like GPT-4 for creative writing tasks and have participated in RLHF projects focused on reducing hallucinations.”
- Ignoring Constraints: If the interview is for a coding role and the AI asks you to solve a problem verbally before typing code, talk through your logic step-by-step. Skipping the verbal reasoning step when asked for it is an automatic fail on platforms like Mercor.
Applying for a Role – Sample Scenarios
When applying for AI training roles, the interview usually pivots from your resume to live logic testing. Here are three common scenarios a bot might throw at you in 2026:
Scenario A: The Ambiguous Prompt
The Question: “Imagine a user asks an AI to ‘Write a story about a bank.’ As an annotator, how do you handle the inherent ambiguity of the word ‘bank’?”
- The “Beginner” Answer (Avoid): “I’d just pick one and write it, or ask the user what they meant.”
- The “Pro” Answer (Win): “I would identify this as a high-entropy prompt. My strategy would be to check the system’s ‘intent-alignment’ guidelines. If the goal is ‘Helpful and Creative,’ I would suggest the model provide a multi-modal response or a story that cleverly bridges both meanings (river bank vs. financial bank). If the guidelines prioritize ‘Directness,’ I would mark it for a ‘clarification’ response to minimize user friction.”
Scenario B: The Hallucination Trade-off
The Question: “Is it ever acceptable for a model to hallucinate in a creative writing task? Where do you draw the line?”
- The Tip: Use the term “Creative Liberty vs. Factual Grounding.” Explain that in fictional contexts, hallucination is “world-building,” but in “Instruction Following,” any deviation from the provided context is a fail. This shows the AI you understand the contextual nature of truth in ML.
Scenario C: The Disagreement
The Question: “What would you do if you disagreed with a peer’s ranking of an AI response during an RLHF session?”
- The Tip: AI hiring bots love “Guideline Supremacy.” Your answer should focus on the documentation. “I would refer back to the project’s Golden Dataset or the specific Annotation Guidelines. If the ambiguity persists, I would document the edge case and escalate it to the Lead Researcher to ensure the model doesn’t receive conflicting signals.”
Common Interview Questions for 2026 Annotators
Be ready to answer these directly into the camera:
- “How does data annotation influence the ‘Ground Truth’ of a model during the fine-tuning phase?”
- Focus on: How consistent labels reduce “noise” and allow the model to converge faster.
- “Explain the difference between a systematic error and a random error in a dataset. Which is more dangerous?”
- Focus on: Systematic errors. Tell the bot that systematic bias (like a mislabeled class) teaches the model “incorrect truths” that are harder to unlearn than random noise.
- “Walk me through a time you had to manage uncertainty when the guidelines were unclear.”
- Focus on: Your logic. Did you create a temporary decision rule? Did you look for patterns in the existing data?
The “Human-in-the-Loop” Edge: What the Bot is Actually Looking For
It is a beautiful irony: an AI is interviewing you to see how well you can teach other AIs to be more human.
The “Avatar” is looking for the things it can’t do yet. It is looking for:
- Nuance: Can you see the “gray area” in a sentiment analysis task?
- Ethics: Can you identify subtle, “jailbroken” prompts that a simpler filter might miss?
- Subjectivity: Can you explain why one poem is “more moving” than another using objective linguistic criteria?
If you treat the interview like a multiple-choice test, you will fail. If you treat it like a masterclass where you are the teacher, you will pass.
Final Thoughts
The AI interview isn’t a barrier; it’s a filter. And like any filter, once you know the mesh size, you can pass through it with ease. By focusing on structured technical communication, metacognition, and guideline adherence, you transform from a “scared applicant” into a “vetted expert.”
In our previous article, we saw the platforms. Today, you have the keys to the gate.
Your Homework:
- Audit your resume: Are your projects described with technical “cluster keywords”? (e.g., “Fine-tuning,” “Contextual Grounding,” “RLHF”).
AI avatars are usually powered by an LLM that “reads” your CV before the camera turns on. If your CV is a mess of fancy graphics, the AI might get confused and ask irrelevant questions.- Standard Formatting: Use a clean, single-column layout. Avoid tables or complex infographics.
- Keyword Loading: Use the specific terminology the AI is programmed to look for.
- Practice with the bot as much as you can: Practice here is the key to success. If you’re on Micro1, use their Interview Prep tool. On Mercor you can retake interviews up to three times, it can help to practice and understand where you fall short.
- Record yourself: Record a 2-minute explanation of a technical concept. Watch it. Are you looking at the lens? Is your background distracting?
The world of 2026 belongs to those who can bridge the gap between human intuition and machine logic. You are that bridge.
Share your thoughts and experiences with the AI interview; we’re collecting experiences and feedback for a “Part 2” of this article!🚀